
We present CosmicMan, a text-to-image foundation model specialized for generating high-fidelity human images. Unlike current general-purpose foundation models that are stuck in the dilemma of inferior quality and text-image misalignment for humans, CosmicMan enables generating photo-realistic human images with meticulous appearance, reasonable structure, and precise text-image alignment with detailed dense descriptions. At the heart of CosmicMan's success are the new reflections and perspectives on data and model: (1) We found that data quality and a scalable data production flow are essential for the final results from trained models. Hence, we propose a new data production paradigm, Annotate Anyone, which serves as a perpetual data flywheel to produce high-quality data with accurate yet cost-effective annotations over time. Based on this, we constructed a large-scale dataset CosmicMan-HQ 1.0, with 6 Million high-quality real-world human images in a mean resolution of 1488x1255, and attached with precise text annotations deriving from 115 Million attributes in diverse granularities. (2) We argue that a text-to-image foundation model specialized for humans must be pragmatic - easy to integrate into down-streaming tasks while effective in producing high-quality human images. Hence, we propose to model the relationship between dense text descriptions and image pixels in a decomposed manner, and present Decomposed-Attention-Refocusing (Daring) training framework. It seamlessly decomposes the cross-attention features in existing text-to-image diffusion model, and enforces attention refocusing without adding extra modules. Through Daring, we show that explicitly discretizing continuous text space into several basic groups that align with human body structure is the key to tackling the misalignment problem in a breeze.
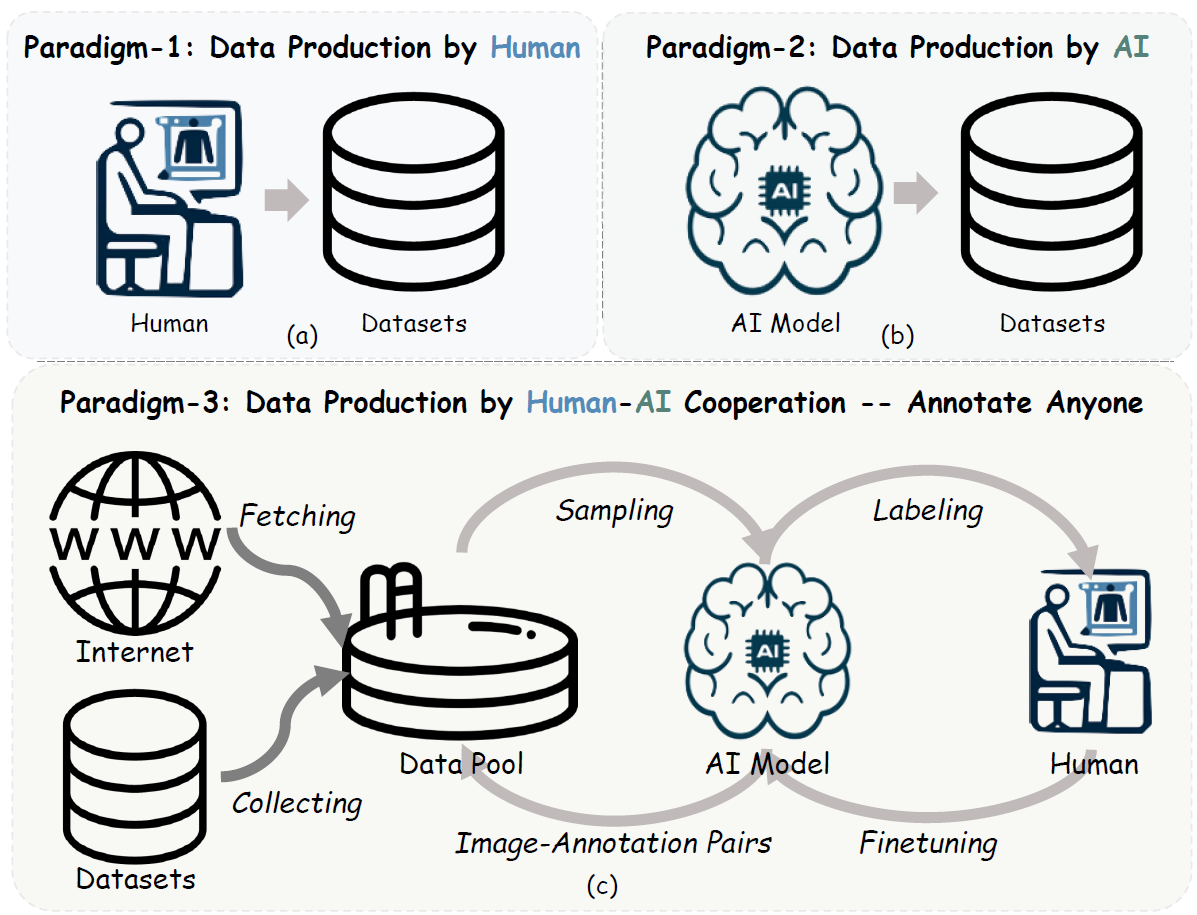
There are two representative data production paradigms: (a) data production by humans and (b) data production by AI. (c) Our proposed new data production paradigm by Human-AI cooperation, named Annotate Anyone. It serves as a data flywheel to produce dynamic up-to-date high-quality data at a low cost.

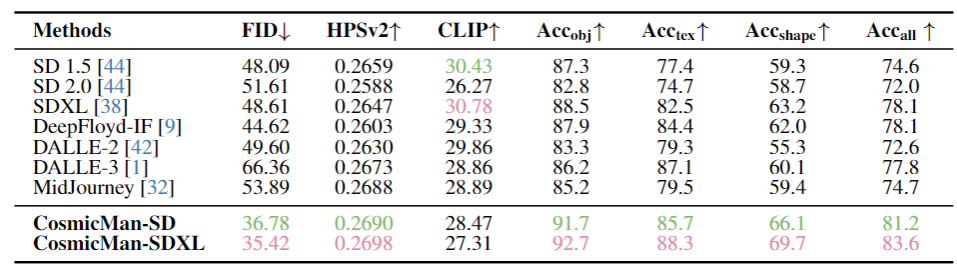
The dataset CosmicMan-HQ 1.0, with 6 Million high-quality real-world human images, will be released soon. The statistical comparison between publicly available human-related datasets and CosmicMan-HQ 1.0.
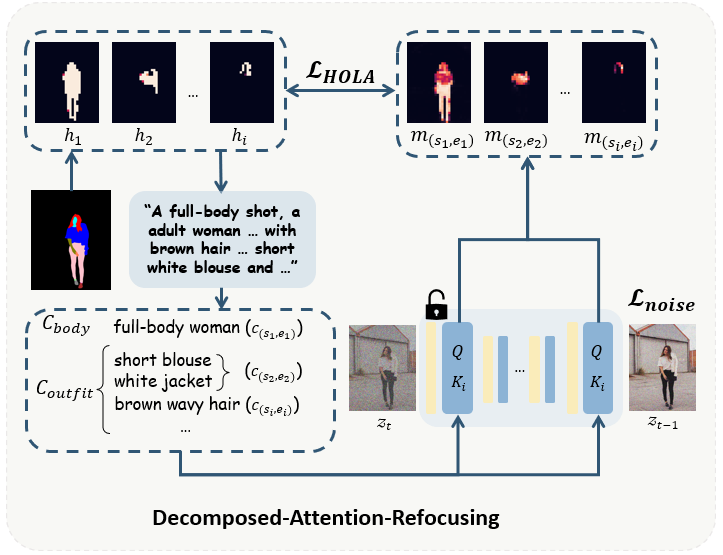
Here we presend the core element of our network. The proposed training framework includes two parts: (1) data discretion for decomposing text-human data into fixed groups that obey human structure; (2) a new loss, called HOLA, to enforce the cross-attention features actively response in the proper spatial region with respect to the scale of body structure and outfit arrangement.







Special thanks to Rongzhang Gu for helping creating demo videos and Yi Zhang for her project management.
@article{li2024cosmicman,
title={CosmicMan: A Text-to-Image Foundation Model for Humans},
author={Li, Shikai and Fu, Jianglin and Liu, Kaiyuan and Wang, Wentao and Lin, Kwan-Yee and Wu, Wayne},
year={2024},
journal = {arXiv preprint},
volume = {arXiv:2404.01294}}